Enrich Full-Stack Feature Store & SDK→
Feature Stores help create, manage, and serve ML features. Features are variables that are derived from raw data using simple to complex transformations. Feature matrices are tables that specify for each entity a value for a feature.
Enrich is a Feature Store designed to generate trusted datasets that can be used for robust analysis and machine learning. It emphasizes the create and manage part of the feature store, and is non-opionated/flexible about the serving part.
The trust is achieved by making the datasets and the generation process:
- Auditable and reproducible
- Documented and discoverable
- Versioned and evolvable
- Customizable and extensible
- Unit-tested
Enrich is a combination of on-prem server-side software and SDK for local development. It is typically deployed as a single-server with the compute being scaled through Dask or PySpark.
The Problem→
There are a number of challenges that organizations face during scaling:
- Efficiency. Organic growth of the usecases results often in separate non-standard infrastructure and process for each. The tech debt built up slows down the whole process.
- Correctness. When there is a discrepancy between analysis done by two individuals or at two points in time, decision making stops to first allow for reconciliation and establishment of ground truth.
- Memory. Often organizations have to revisit decisions made sometime in the past. It is necessary to keep the datasets around along with enough detail to understand and reproduce the results.
- Newer Requirements. GDPR-like laws are being passed in all geographies, and they require that the modeling and anlysis be privacy law aware and safe. There requires a system to monitor the data generation and access processes.
Scaling up analysis and modeling requires system, process, and data that is:
- Trustworthy and well-documented
- Relevant
- Standardized
- Readily available
- Efficient
Platform→
The platform puts together selected pieces from the state of art data science ecosystem, and organizes them to make it easy to deliver data usecases.
Enrich architecture's goals include:
- Minimality and fit for purpose
- Usability and trust in the computation
- Scalability with the number of applications
Explicit non-goals are:
- Replacement for BI or Data Science platforms
- Arbitrary scalability with petabytes
- Great visualization and self-serve interfaces
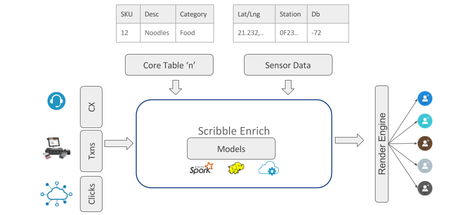
In order to achieve these objectives, Enrich has selected and rearranged pieces from the data science ecosystem. In particular it has created:
- Local development framework for unit-tested data transforms
- Server-side execution framework with parameterization, metadata management, expectations etc.
- Extensible GUI framework that allows data products to be built by Scribble and the user.
- Out of the box modules including feature marketplace, catalog, provenance search
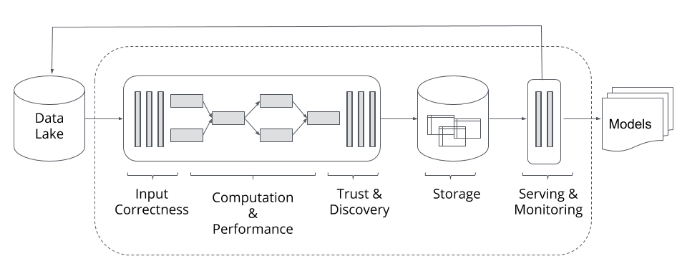
Terminology→
- Pipelines - long running, multi-step data-intensive processes
- Task - Short processes
- Services - Continuously running background processes
- Apps - Extensible GUI to create interfaces/dashboards fast
- Workflows - Sequence of pipelines
Each of these is themselves built out of subcomponents such as transforms (data processing units), assets (libraries), and SDK (development library).
This SDK enables solution developers to build and test computational and rendering modules.